更新
LCDを表示するぶぶんを「その2」に記載した。
なお、ここで説明した時のソースは以下のcommitとなる。
目的
TensorFlow Lite for microのサンプル(Hello world)をM5StickV向けにビルド、動作させる。今回は、サンプルをそのまま動作させて、シリアルで結果が得られるところまでを確認する。
動機
前回、
前々回のブログでTensorFlow Lite for microをRISC-Vプロセッサ向けにビルド・Qemuで動作させることを試した。やっぱり、実際のモノ(マイコンとか、実機)で動かしてみたいと思った。そういえば、M5StickVのCPUはRISC-V 64 bitなので、もしかしたらうまくいくかもしれないと思い、試してみた。
ビルドまでの道のり
ここでは、前々回のブログで用いたリポジトリ(本家からのfork)を使う。このため、最新では異なることがあるので注意。
ビルドできるまでのいろいろなことを記載する。
コンパイラ
M5StickV向けのコンパイラは、以下で公開しているものを使った。
Kendryte K210 standalone SDK
non OS向けのSDKが公開されている。
リンカスクリプトやBSP、ドライバのSDKが付属し、cmakeを利用してビルドできる。このリポジトリの
src配下にターゲットとなるソースを配置し、
CMakeLists.txtを編集することで、目的のバイナリがビルドできる。
kflash_gui
M5StickVのバイナリ書き込みツール。
(メインで使っている)Fedora 30ではうまく起動できなかったため、Windows版を利用する。
TensorFlow Lite for microの構成
Makefile
大本のMakefileは以下。ビルド時にターゲットCPUとビルドするアプリケーション(プロジェクト)を指定する。
前回指定したRISC-V 32bit、hello worldのサンプルの場合、この辺りも参照する。
riscv32_mcu/Makefile.inc は、
#33972 のRISC-Vターゲットでビルドが失敗する問題を解消するためである。これは、今時点(2020.1.19)で取り込まれていないため注意。
3rd party ライブラリ
TensorFlow以外のライブラリは以下を使用している。
上記以外では、ターゲット固有のSDKやtoolchainであるため、ここでは省略。なお、gemmlowp、flatbuffersともヘッダーファイルだけを使用する。
ファイル構成
hello worldのビルドに必要なソース・ヘッダファイルの構成は以下。microがどのようなファイルを必要としているのか、見渡せるようにする。本体と比べれば、ファイル数は少ない。
tensorflow
├ tensorflow
| ├ core
| | └ public
| | └ version.h
| └ lite
| ├ c
| | ├ builtin_op_data.h
| | ├ common.c
| | └ common.h
| ├ core
| | └ api
| | ├ error_reporter.cc
| | ├ error_reporter.h
| | ├ flatbuffer_conversions.cc
| | ├ flatbuffer_conversions.h
| | ├ op_resolver.cc
| | ├ op_resolver.h
| | ├ tensor_utils.cc
| | └ tensor_utils.h
| ├ kernels
| | ├ internal
| | | ├ optimized
| | | | └ neon_check.h
| | | ├ reference
| | | | ├ integer_ops
| | | | | ├ add.h
| | | | | ├ conv.h
| | | | | ├ depthwise_conv.h
| | | | | ├ fully_connected.h
| | | | | ├ mul.h
| | | | | ├ pooling.h
| | | | | └ softmax.h
| | | | ├ add.h
| | | | ├ arg_min_max.h
| | | | ├ binary_function.h
| | | | ├ ceil.h
| | | | ├ comparisons.h
| | | | ├ concatenation.h
| | | | ├ conv.h
| | | | ├ depthwiseconv_float.h
| | | | ├ depthwiseconv_uint8.h
| | | | ├ dequantize.h
| | | | ├ floor.h
| | | | ├ fully_connected.h
| | | | ├ logistic.h
| | | | ├ maximum_minimum.h
| | | | ├ mul.h
| | | | ├ neg.h
| | | | ├ pad.h
| | | | ├ pooling.h
| | | | ├ prelu.h
| | | | ├ process_broadcast_shapes.h
| | | | ├ quantize.h
| | | | ├ round.h
| | | | ├ softmax.h
| | | | └ strided_slice.h
| | | ├ common.h
| | | ├ compatibility.h
| | | ├ quantization_util.cc
| | | ├ quantization_util.h
| | | ├ round.h
| | | ├ scoped_profiling_label_wrapper.h
| | | ├ strided_slice_logic.h
| | | ├ tensor.h
| | | ├ tensor_ctypes.h
| | | └ types.h
| | ├ kernel_util.cc
| | ├ kernel_util.h
| | ├ op_macros.h
| | └ padding.h
| ├ micro
| | ├ examples
| | | └ hello_world
| | | ├ constants.cc
| | | ├ constants.h
| | | ├ main.cc
| | | ├ main_functions.cc
| | | ├ main_functions.h
| | | ├ output_handler.cc
| | | ├ output_handler.h
| | | ├ sine_model_data.cc
| | | └ sine_model_data.h
| | ├ kernels
| | | ├ activations.cc
| | | ├ activation_utils.h
| | | ├ add.cc
| | | ├ all_ops_resolver.cc
| | | ├ all_ops_resolver.h
| | | ├ arg_min_max.cc
| | | ├ ceil.cc
| | | ├ comparisons.cc
| | | ├ concatenation.cc
| | | ├ conv.cc
| | | ├ depthwise_conv.cc
| | | ├ dequantize.cc
| | | ├ elementwise.cc
| | | ├ floor.cc
| | | ├ fully_connected.cc
| | | ├ logical.cc
| | | ├ logistic.cc
| | | ├ maximum_minimum.cc
| | | ├ micro_ops.h
| | | ├ micro_utils.h
| | | ├ mul.cc
| | | ├ neg.cc
| | | ├ pack.cc
| | | ├ pad.cc
| | | ├ pooling.cc
| | | ├ prelu.cc
| | | ├ quantize.cc
| | | ├ reshape.cc
| | | ├ round.cc
| | | ├ softmax.cc
| | | ├ split.cc
| | | ├ strided_slice.cc
| | | ├ svdf.cc
| | | └ unpack.cc
| | ├ memory_planner
| | | ├ greedy_memory_planner.cc
| | | ├ greedy_memory_planner.h
| | | ├ linear_memory_planner.cc
| | | ├ linear_memory_planner.h
| | | └ memory_planner.h
| | ├ riscv64_mcu
| | | ├ debug_log.cc
| | | └ README.md
| | ├ tools
| | | └ make
| | | └ downloads
| | | ├ flatbuffers
| | | | ├ include
| | | | | └ flatbuffers
| | | | | ├ base.h
| | | | | ├ flatbuffers.h
| | | | | └ stl_emulation.h
| | | | └ LICENSE.txt
| | | └ gemmlowp
| | | ├ fixedpoint
| | | | ├ fixedpoint.h
| | | | └ fixedpoint_sse.h
| | | ├ internal
| | | | └ detect_platform.h
| | | └ LICENSE
| | ├ compatibility.h
| | ├ debug_log.h
| | ├ debug_log_numbers.cc
| | ├ debug_log_numbers.h
| | ├ memory_helpers.cc
| | ├ memory_helpers.h
| | ├ micro_allocator.cc
| | ├ micro_allocator.h
| | ├ micro_error_reporter.cc
| | ├ micro_error_reporter.h
| | ├ micro_interpreter.cc
| | ├ micro_interpreter.h
| | ├ micro_mutable_op_resolver.cc
| | ├ micro_mutable_op_resolver.h
| | ├ micro_optional_debug_tools.cc
| | ├ micro_optional_debug_tools.h
| | ├ micro_utils.cc
| | ├ micro_utils.h
| | ├ simple_memory_allocator.cc
| | ├ simple_memory_allocator.h
| | ├ test_helpers.cc
| | └ test_helpers.h
| ├ schema
| | └ schema_generated.h
| ├ string_type.h
| ├ string_util.h
| ├ type_to_tflitetype.h
| └ version.h
├ AUTHORS
└ LICENSE
デバッグログの出力
HWやtoolchain固有の部分であり、DebugLog関数を実装することになる。RISC-V向けには、RISC-V 32bitをそのまま流用することで、シリアルにログが出力される。
ビルドプロジェクト
今回は、TensorFlow Lite for microのMakefileを使用するのではなく、Kendryte K210 standalone SDKのcmakeを使ってのビルド方法にした(そのほうが楽そうだった)。
ビルド用のプロジェクトは以下で公開している。
TensorFlow Lite for microのhello worldで使用するソース・ヘッダファイルのみを
src配下に格納する。
※tensorflowすべてのファイルを格納してしまうと、SDK内でヘッダファイルの競合が発生するため、必要なファイルのみとした。
CMakeLists.txtには、必要なヘッダのパス、ソースファイルの一覧を記載する。また、前々回のブログでも記載した、std::roundの参照エラー(
#35302)の回避のために、以下の定義を追加しておく。あと、Kendryte K210 standalone SDKが便利なマクロを用意してくれるので助かる。
M5StickV向けのビルドで発生するビルドエラーの回避
1か所、ビルドエラーが発生するためにソースを修正する。
std::minの第二引数「(1ll << 31) - 1.0」がfloatであるといわれて、第一引数「beta * input_scale * (1 << (31 - input_integer_bits))」のdoubleと型が不一致だと怒られてしまう。第二引数「(1ll << 31) - 1.0」はdoubleではないのか?(しかも、前々回のブログではエラーとならなかった...)のでもしかしたら、toolchainによるものかも?
とりあえず、doubleにキャストすることで回避する。
ビルド
kflash_guiが(自分の環境だと)Windowsでしか動かないのでWindows 10でビルドする。
Windows版のCMakeをインストールする。
PowerShellで操作。
> git clone https://github.com/NobuoTsukamoto/m5stickv-tensorflow-lite-micro.git
> $env:Path="\kendryte-toolchain\bin;C:\Program Files\CMake\bin;" + $env:Path
> cd m5stickv-tensorflow-lite-micro\src\micro
> mkdir build
> cd build
> cmake -G "MinGW Makefiles" ../../../..
> make
ビルド後、buildディレクトリに「micro」と「micro.bin」のファイルができる。
「micro.bin」ファイルをkflash_guiでM5StickVに焼けばOK。
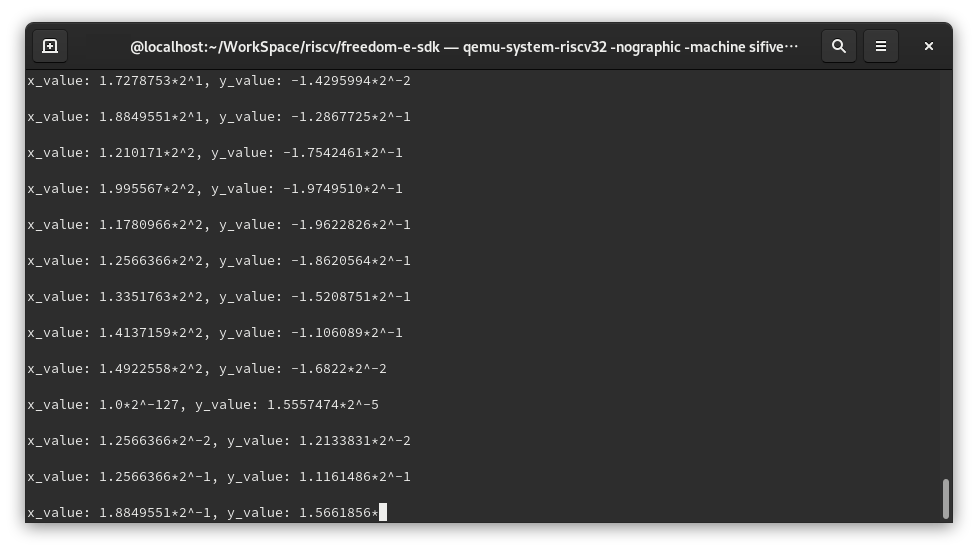
結果
Teratermで接続すると、シリアルにログが出力される。
次回
つぎは、M5StickVのLCDに結果表示するために行ったことを記載する。